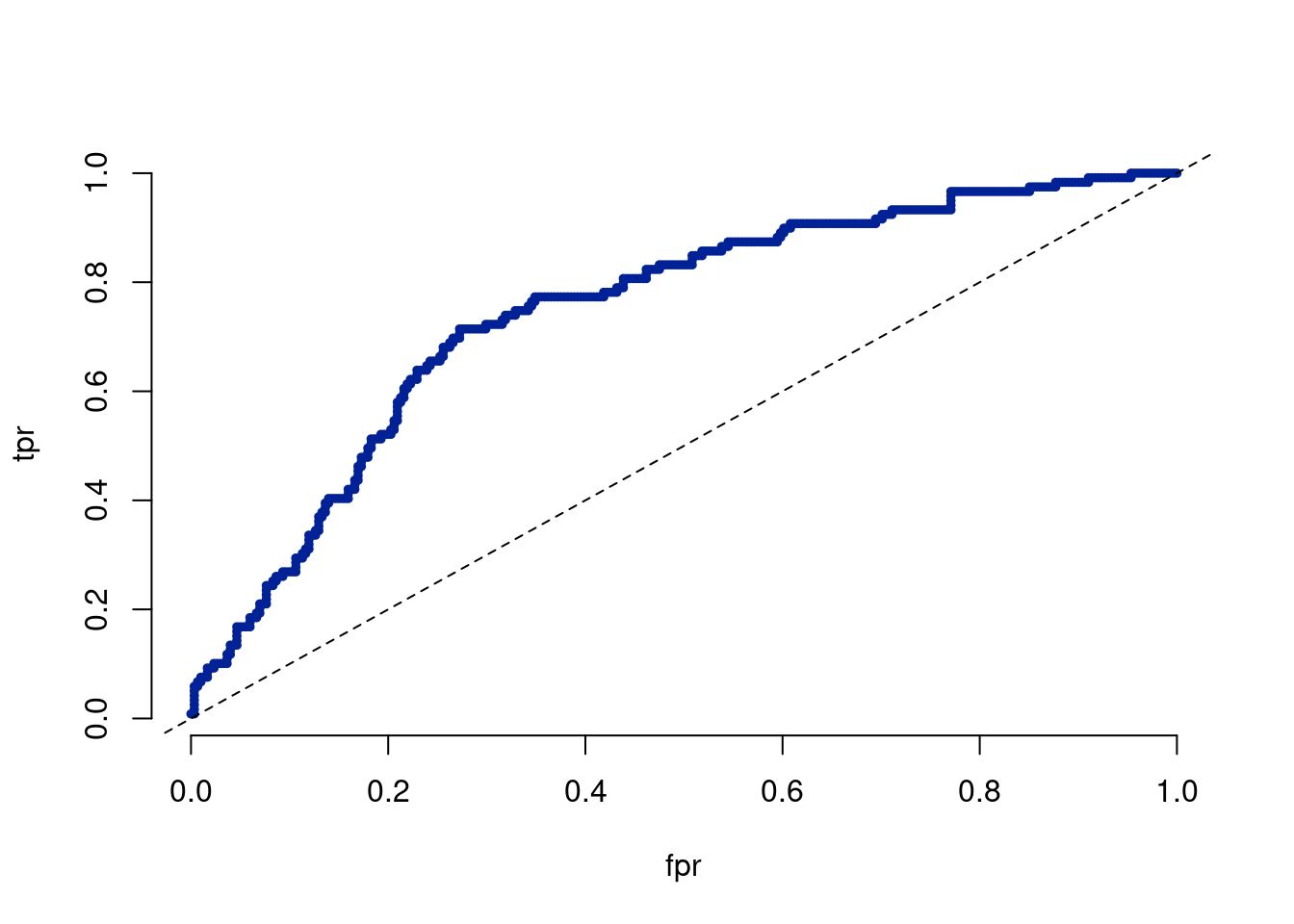
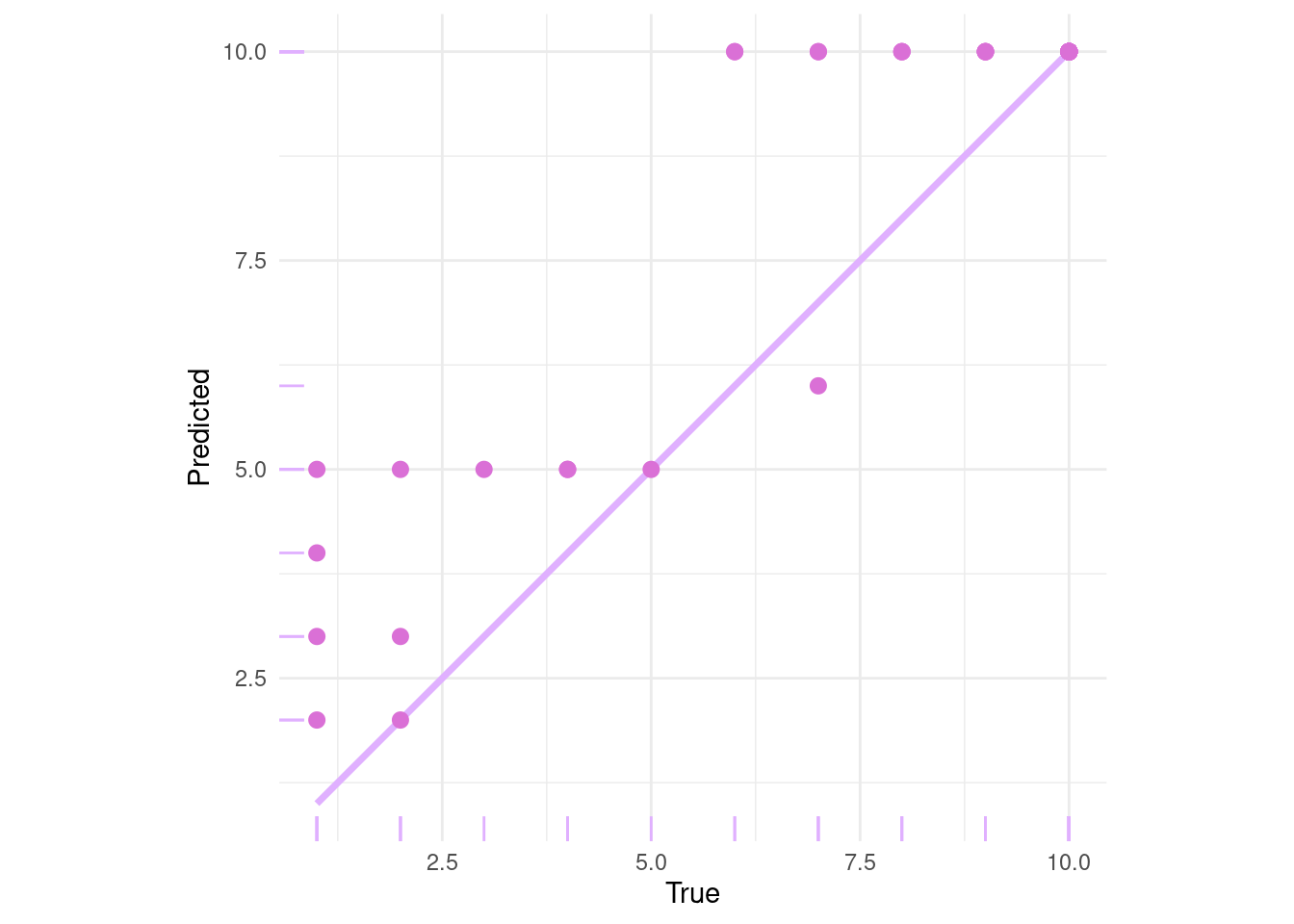
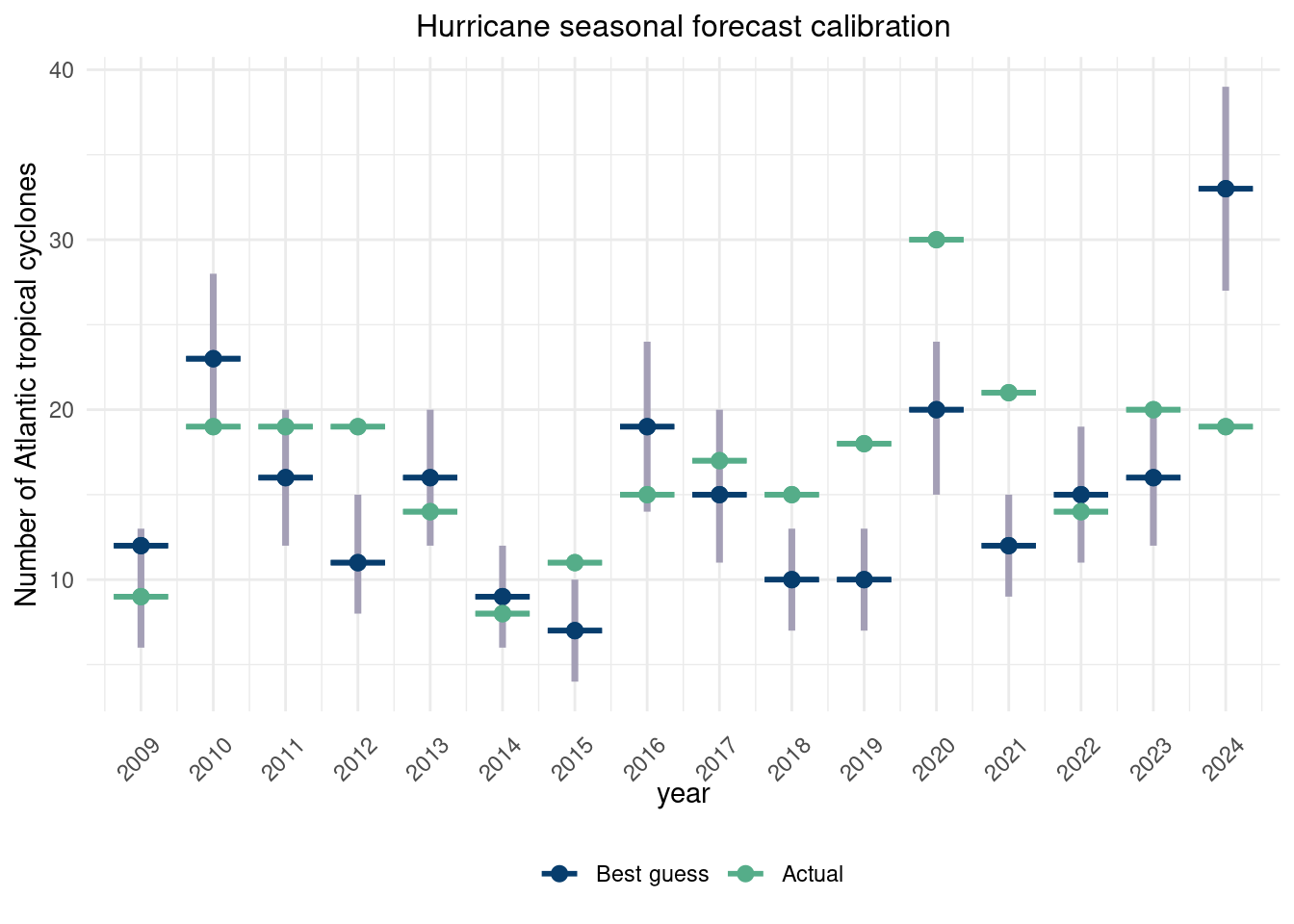
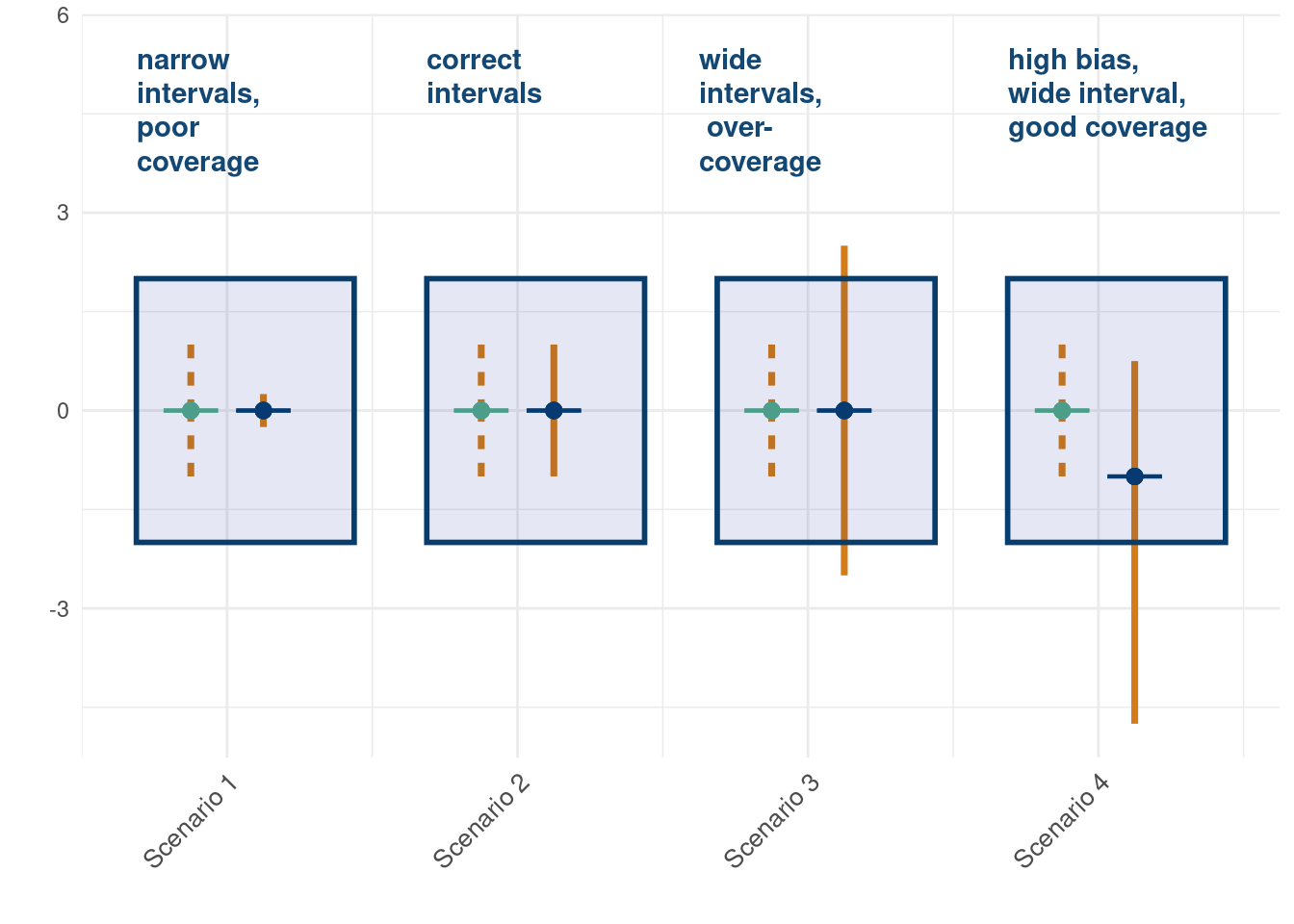
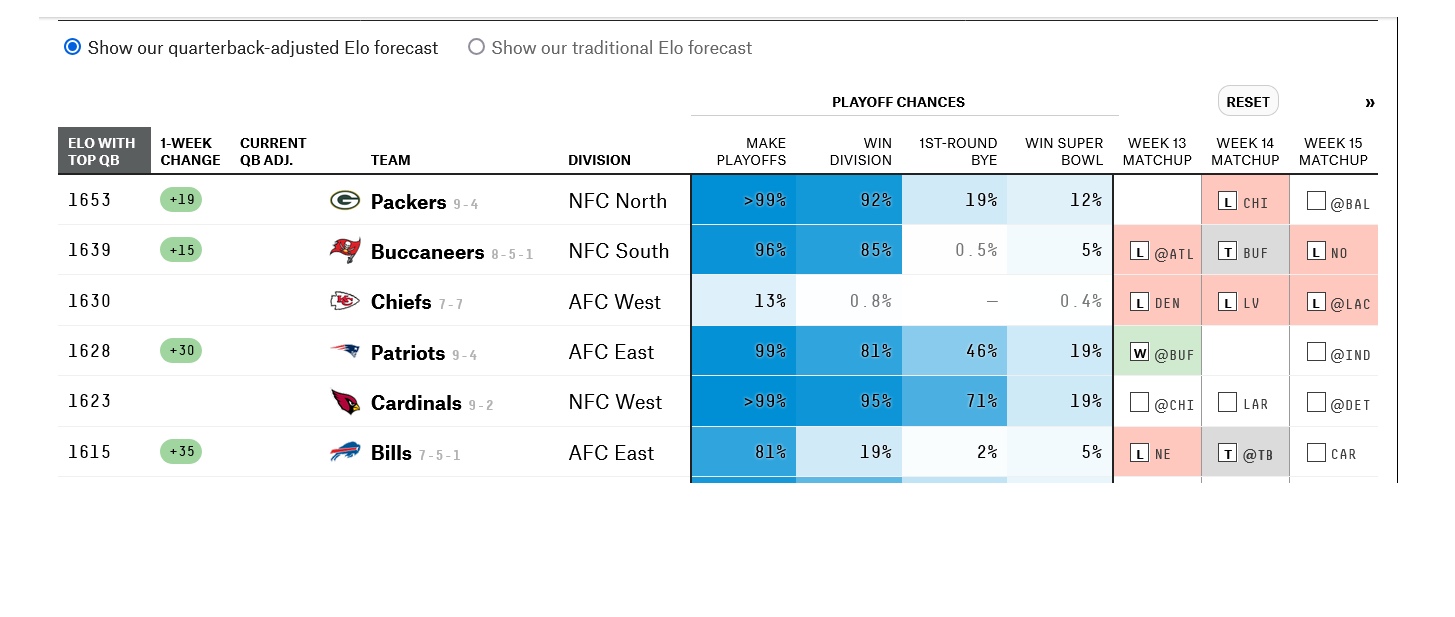
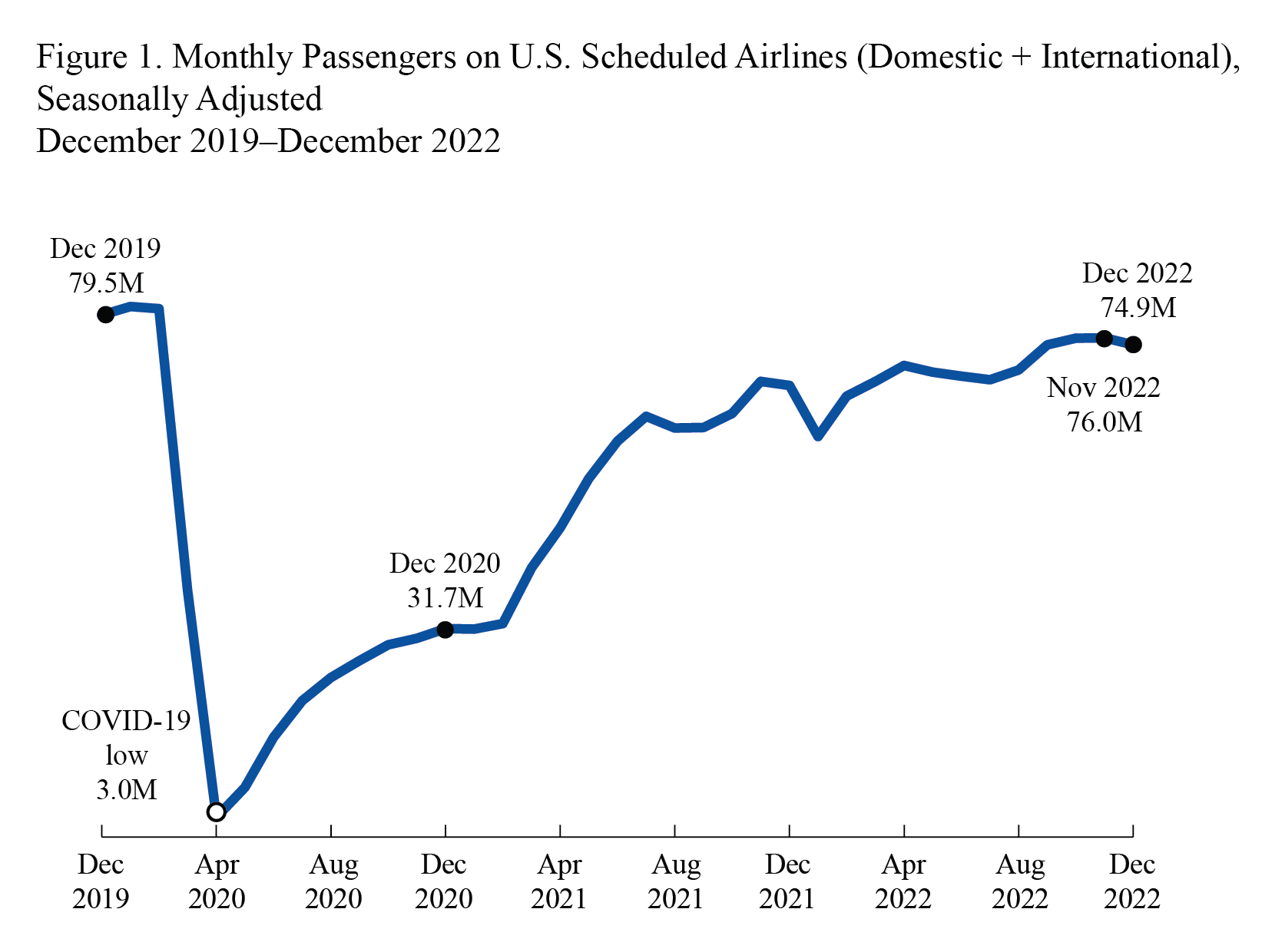
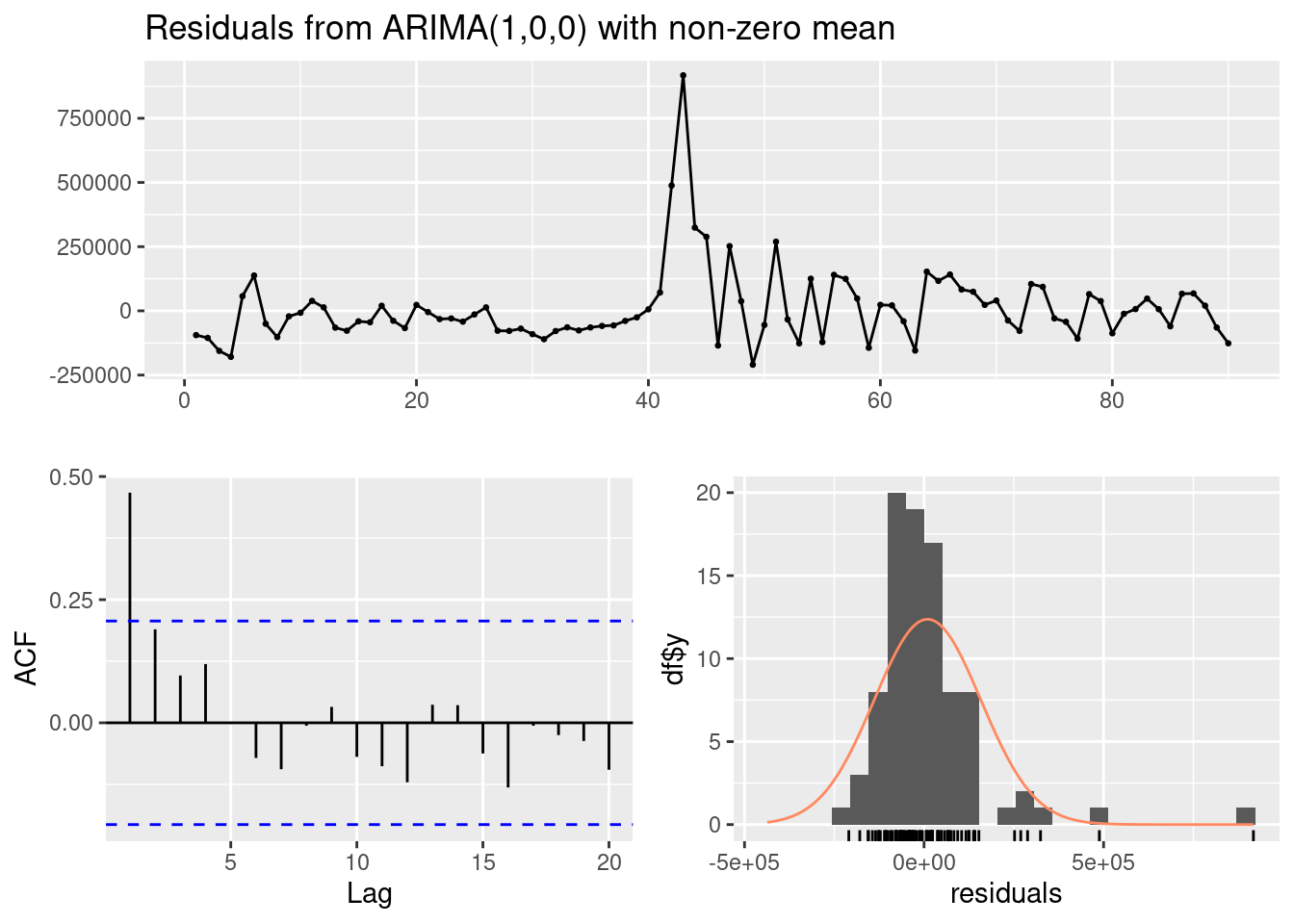
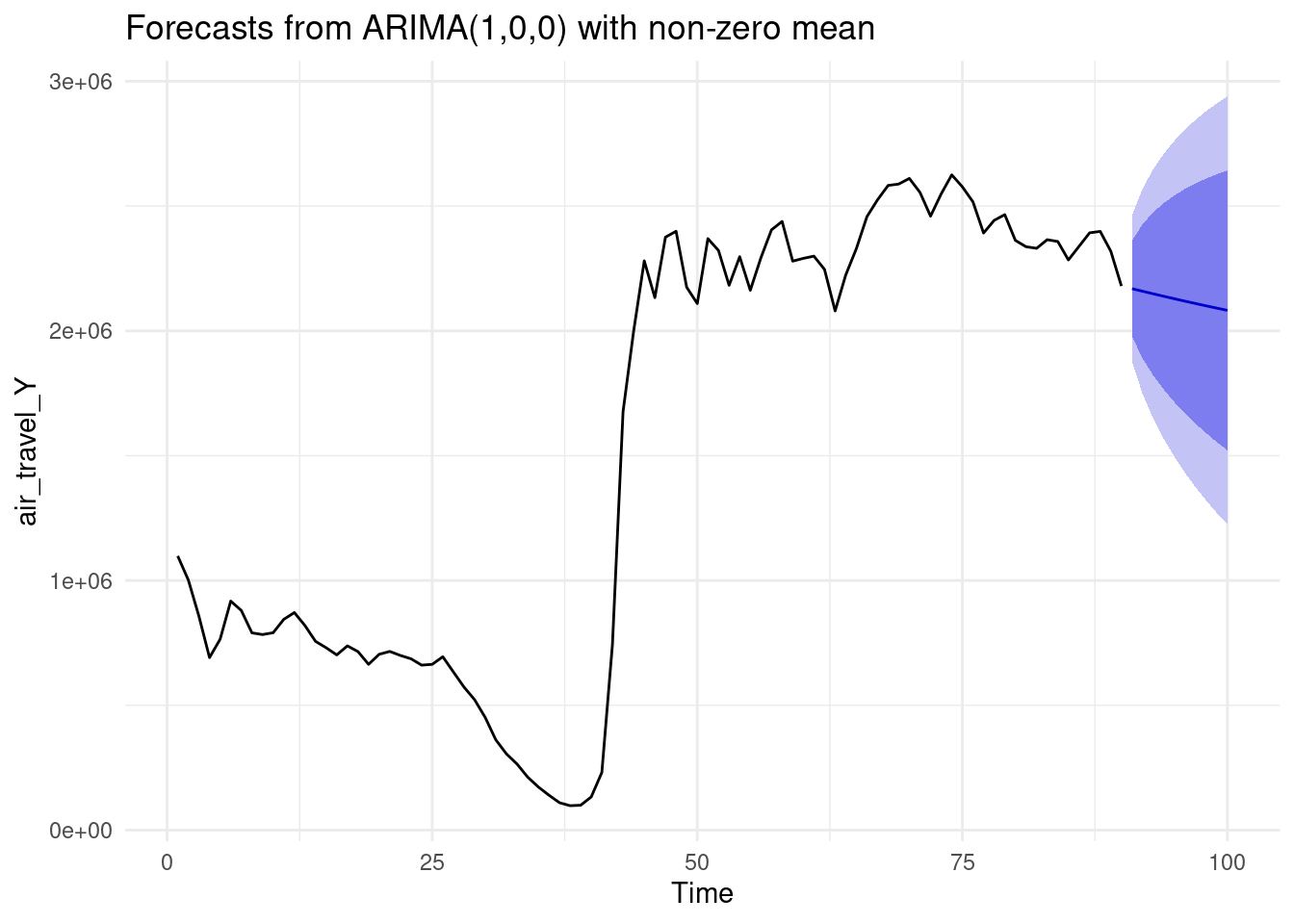
*****Calling gbart: type=2
*****Data:
data:n,p,np: 359, 18, 63
y1,yn: 0.000000, 0.000000
x1,x[n*p]: 27.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.91329
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 1s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 349, 18, 63
y1,yn: 0.000000, 0.000000
x1,x[n*p]: 27.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.78354
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 2s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 336, 18, 63
y1,yn: 1.000000, 0.000000
x1,x[n*p]: 27.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.73166
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 1s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 322, 18, 63
y1,yn: 1.000000, 0.000000
x1,x[n*p]: 23.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.74638
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 2s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 309, 18, 63
y1,yn: 1.000000, 0.000000
x1,x[n*p]: 29.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.62784
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 1s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 293, 18, 63
y1,yn: 0.000000, 0.000000
x1,x[n*p]: 26.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.60173
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 1s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 277, 18, 63
y1,yn: 1.000000, 0.000000
x1,x[n*p]: 26.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.71338
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 1s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 265, 18, 63
y1,yn: 0.000000, 0.000000
x1,x[n*p]: 24.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.82551
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 2s
trcnt,tecnt: 250,250
*****Calling gbart: type=2
*****Data:
data:n,p,np: 256, 18, 63
y1,yn: 1.000000, 0.000000
x1,x[n*p]: 24.000000, 0.000000
xp1,xp[np*p]: 25.000000, 0.000000
*****Number of Trees: 50
*****Number of Cut Points: 14 ... 1
*****burn,nd,thin: 250,2500,10
*****Prior:beta,alpha,tau,nu,lambda,offset: 2,0.95,0.212132,3,1,-1.63733
*****Dirichlet:sparse,theta,omega,a,b,rho,augment: 0,0,1,0.5,1,18,0
*****printevery: 2500
MCMC
done 0 (out of 2750)
done 2500 (out of 2750)
time: 1s
trcnt,tecnt: 250,250